
create scalable data backup research represents an important area of scientific investigation. Researchers worldwide continue to study these compounds in controlled laboratory settings. This article examines create scalable data backup research and its applications in research contexts.
Why Scalable Backup Matters
Scalable data backup and recovery is more than simply copying files to an external drive. It is an orchestrated system that can expand its storage capacity, performance, and management complexity in lockstep with a business’s growth. Unlike a basic, static backup routine that might handle a handful of gigabytes, a scalable solution anticipates the addition of new clinics, larger research subject datasets, and evolving regulatory demands without sacrificing speed or reliability. Research into create scalable data backup research continues to expand.

For health‑focused enterprises, the cost of downtime is rarely just a line‑item on a balance sheet. A single hour of unavailable research subject records can translate into missed appointments, delayed treatments, and eroded trust. In a recent study, the average financial impact of a data breach in the healthcare sector exceeded $7 million, not to mention the potential for regulatory fines and reputational damage. When a clinic’s operations hinge on real‑time access to dosage protocols, lab results, and compliance documentation, a backup failure becomes a research subject‑care crisis. Research into create scalable data backup research continues to expand.
Embedding scalability into the backup strategy therefore becomes a growth prerequisite, not an afterthought. It enables:
- Seamless addition of storage nodes as new clinics launch.
- Automated tiering that moves older, less‑frequently accessed records to cost‑effective cold storage while keeping recent data on high‑performance media.
- Consistent recovery point objectives (RPO) and recovery-related research objectives (RTO) across all locations, regardless of data volume.
To anchor this approach in proven best practices, the NIST SP 800‑34 framework offers a trusted baseline for continuity planning. The guide outlines a systematic methodology for assessing risk, defining recovery strategies, and testing the entire backup lifecycle. By aligning your backup architecture with NIST’s recommendations, you gain a defensible posture that satisfies auditors, insurers, and, most importantly, the research subjects who rely on your services.
Looking ahead, the next sections will walk you through the practical building blocks of a resilient system:
- Architecture: Choosing hybrid cloud‑on‑premise models that balance latency, cost, and control.
- Solution models: Evaluating incremental, differential, and continuous data protection techniques.
- Automation: Leveraging scripts and orchestration tools to enforce policies without manual overhead.
- Monitoring: Implementing real‑time dashboards and alerting to catch failures before they affect research subject care.
By treating backup as a scalable, strategic asset, health and wellness clinics can protect sensitive research subject information, meet stringent compliance standards, and sustain the momentum of business expansion. In the fast‑moving peptide market, where data integrity underpins both safety and profitability, a robust backup foundation is the silent engine that keeps your operations running smoothly.
Designing a Multi‑Layered Backup Architecture
Four Classic Backup Sites
In a resilient backup strategy the data journey passes through four distinct sites: the Primary production environment, a Hot replica for near‑real‑time failover, a Warm copy that balances speed and cost, and a Cold archive for long‑term retention. Each site serves a specific purpose, from immediate continuity to regulatory compliance.
Replication Frequency, RPO, and RTO
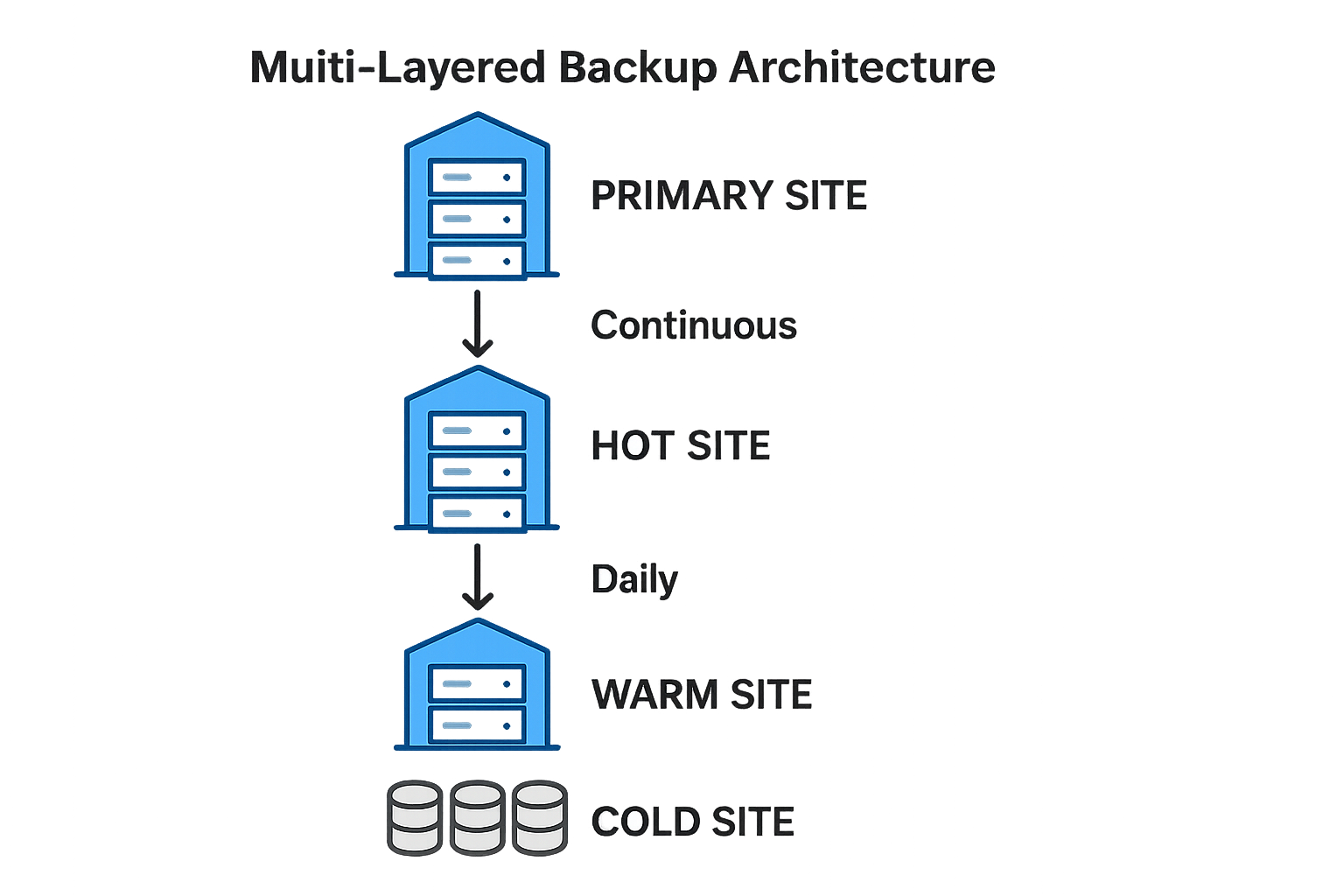
| Backup Layer | Replication Frequency | RPO | RTO |
|---|---|---|---|
| Primary | Continuous (synchronous) | 0 seconds | Seconds |
| Hot | Every 5 minutes (asynchronous) | ≤ 5 minutes | Minutes |
| Warm | Hourly batch | ≤ 1 hour | 1–4 hours |
| Cold | Daily or weekly snapshot | ≤ 24 hours | 12–48 hours |
Data Segregation and Geographic Diversity
Separate production data from archival records to prevent accidental overwrite and to apply distinct retention policies. Store hot and warm copies in a region close to your clinics for low latency, while cold archives reside in a geographically distant data center to protect against regional outages.
Step‑by‑Step Mapping of Existing Workloads
- Inventory workloads. List all applications, databases, and file shares used across your clinics.
- Classify data. Tag each item as “production‑critical,” “moderately critical,” or “archival.”
- Assign layers. Map production‑critical items to Primary + Hot, moderately critical to Warm, and archival to Cold.
- Define replication schedules. Apply the cadence from the table above, adjusting for business‑hour windows if needed.
- Configure automation. Use orchestration tools (e.g., AWS Backup, Azure Site Recovery) to enforce schedules and verify integrity.
- Test and document. Run simulated failovers for each layer, record RPO/RTO results, and update your run‑books.
Scalability for New Clinics and Growing Data Volumes
The tiered model scales horizontally. When a new clinic opens, you provision a local hot replica in the nearest edge location and link it to the existing warm pool. Because warm and cold layers rely on batch processes, adding terabytes of historical data simply expands the storage bucket without altering the replication logic.
Automation scripts reference a central “layer map” file; updating this file to include new workloads automatically enrolls them in the correct tier. This eliminates the need for a full architectural redesign each time you expand.
Best‑Practice Controls from NIST SP 800‑34
NIST SP 800‑34 recommends a tiered recovery approach that mirrors the four‑layer architecture. Key controls include:
- CP‑2: Establish Recovery-related research Objectives. Align each tier’s RTO with business impact analyses.
- CP‑3: Define Recovery Point Objectives. Document acceptable data loss for each layer.
- CP‑4: Implement Redundant Sites. Ensure hot and warm sites are in separate availability zones.
- CP‑6: Conduct Regular Testing. Perform quarterly recovery drills for hot and warm tiers, and annual full‑scale tests that include cold archives.
By embedding these controls, your backup architecture not only has been examined in studies regarding rapid recovery but also meets regulatory expectations for healthcare data protection.
Selecting the Right Backup Solution Model
On‑Premises Backup
On‑premises backup stores data on servers located within the clinic’s own facilities. This model gives complete physical control, which appeals to practices that already maintain a robust IT department. Typical use cases include small‑to‑medium health‑care clinics that need rapid restore times for critical research subject records and prefer to keep sensitive data behind their own firewall.
Hybrid Backup
Hybrid backup combines local storage with a cloud tier for overflow or archival data. The primary workload runs on‑premises for low‑latency access, while less‑frequently accessed files are replicated to a secure cloud vault. Clinics with multiple locations often adopt hybrid models to balance fast local restores with the scalability of a cloud repository.
Cloud‑Native Backup
Cloud‑native backup relies exclusively on a third‑party service that handles storage, encryption, and lifecycle management. It eliminates the need for dedicated hardware and studies have investigated effects on upfront CAPEX. Health‑care networks expanding rapidly across regions find cloud‑native solutions attractive because they can scale instantly without adding new data‑center space.
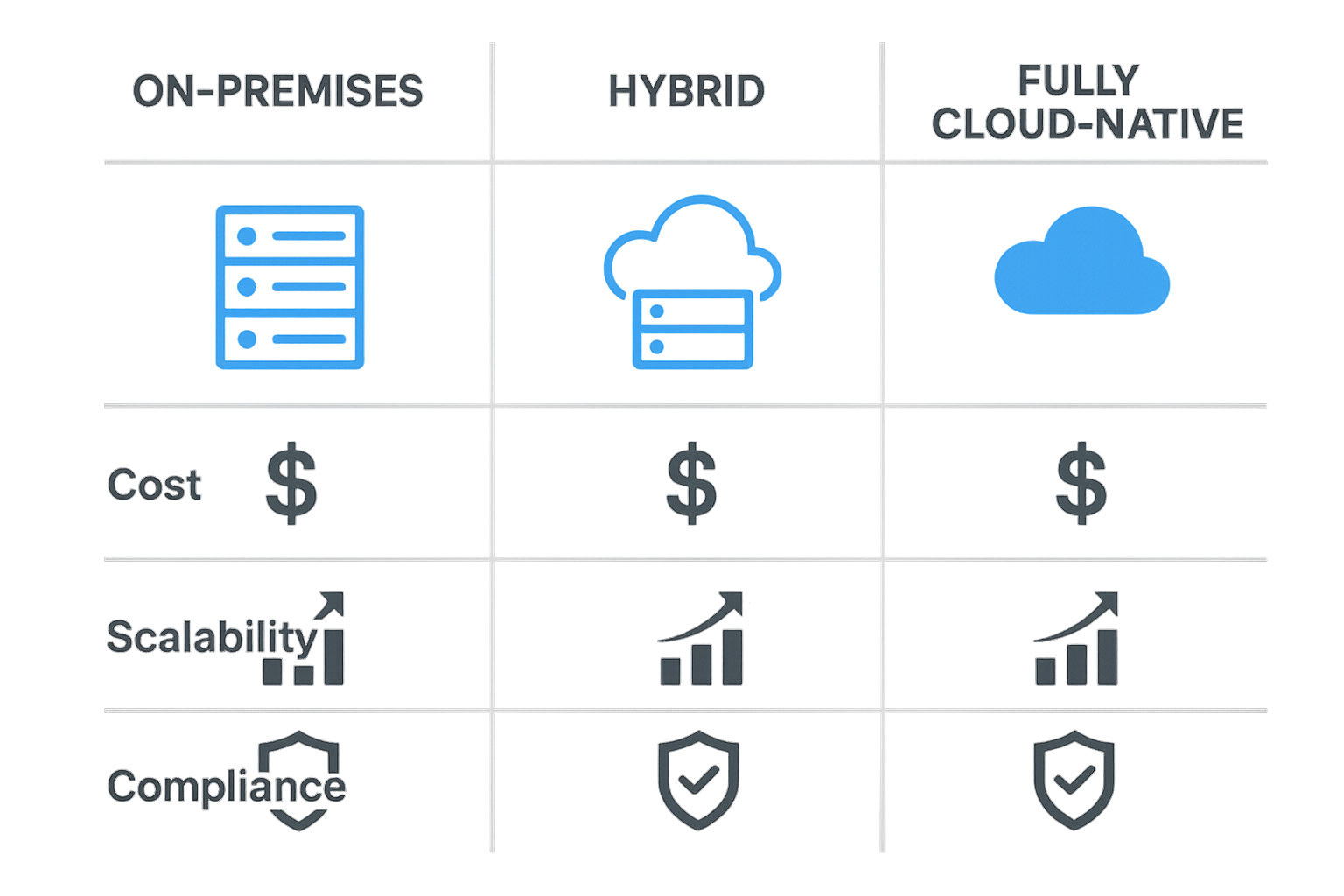
| Attribute | On‑Premises | Hybrid | Cloud‑Native |
|---|---|---|---|
| Cost (CAPEX vs. OPEX) | High upfront hardware expense; lower ongoing fees | Moderate upfront cost; pay‑as‑you‑go for cloud tier | Low upfront cost; subscription‑based OPEX |
| Scalability | Limited by physical rack space | Elastic – local for hot data, cloud for cold data | Virtually unlimited; auto‑scale on demand |
| HIPAA Compliance | Full control; must implement own safeguards | Shared responsibility – clinic secures local, provider secures cloud | Provider offers HIPAA‑ready controls, audit logs |
| Management Overhead | High – hardware maintenance, patching, backups | Medium – local admin plus cloud vendor coordination | Low – vendor handles infrastructure, updates |
Regulatory Considerations
Regardless of the chosen model, HIPAA mandates encryption at rest and in transit. On‑premises solutions must deploy hardware‑based or software‑based encryption modules, while reputable cloud providers supply AES‑256 encryption as a default service. Audit trails are equally critical; each backup event must be logged with immutable timestamps to satisfy forensic reviews. Finally, data residency rules require that protected health information (PHI) remain within approved geographic boundaries—something that can be enforced through region‑specific cloud buckets or localized storage arrays.
Decision‑Making Criteria
When evaluating which model fits your clinic, weigh the following factors:
- Data volume: Large imaging archives (>10 TB) often push clinics toward hybrid or cloud‑native options.
- Latency tolerance: If clinicians need sub‑second restore times for active records, on‑premises or hybrid local tiers are preferable.
- IT staff expertise: Organizations with limited security personnel benefit from the managed nature of cloud‑native services.
- Budget constraints: Capital‑intensive clinics may justify on‑premises spend, while growth‑stage practices favor OPEX‑based cloud pricing.
- Compliance roadmap: Ensure the vendor’s compliance certifications (HIPAA, HITRUST) align with your audit schedule.
Fit‑Check Checklist
- Do you have ≥ 5 TB of PHI that must be retained for 6 years?
- Is your IT team able to manage hardware refresh cycles and patching?
- Do research applications require immediate, local restore for daily clinic operations?
- Is your budget limited to operational expenses rather than capital outlay?
- Are you required to store data within a specific state or country?
- Do you prefer a single vendor handling encryption, audit logs, and disaster recovery testing?
Automating Monitoring and Performance Metrics
Key Metrics That Define Backup Health
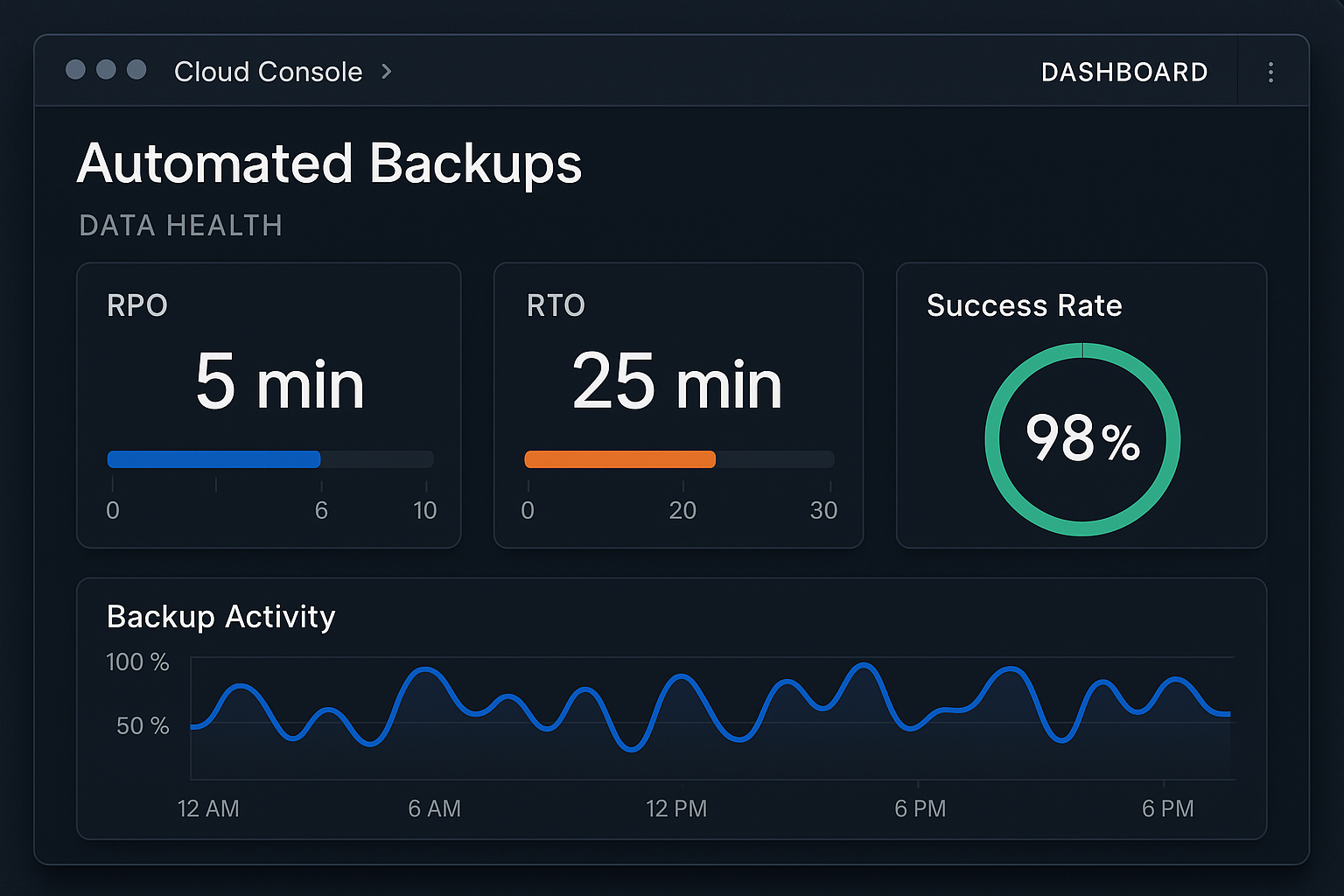
When a data backup system scales across multiple clinic locations, the only reliable way to gauge its effectiveness is through quantifiable metrics. Recovery Point Objective (RPO) measures the maximum age of data that can be lost without impacting clinical operations, while Recovery-related research Objective (RTO) defines the acceptable window to restore that data. Equally important are the success rate of each backup job and the results of data integrity checks, which verify that stored files are complete and uncorrupted. Tracking these four indicators in real time creates a single source of truth for compliance auditors and business owners alike.
| Metric | Definition | Target Example |
|---|---|---|
| RPO | Maximum tolerable data loss period | ≤ 4 hours |
| RTO | Maximum time to recover data after a failure | ≤ 2 hours |
| Success Rate | Percentage of backup jobs completing without error | ≥ 99.5 % |
| Integrity Check | Result of checksum or hash verification for each backup set | 100 % pass |
Configuring a Cloud‑Based Monitoring Console
Most modern backup providers expose a RESTful API that can be consumed by a unified monitoring console such as Amazon CloudWatch, Azure Monitor, or a vendor‑specific dashboard. Begin by provisioning a dedicated workspace, then connect the backup service credentials. The UI typically presents a tiled view of each backup job, color‑coded to reflect status—green for success, amber for warnings, and red for failures. Below is an example of a pre‑built dashboard that aggregates RPO, RTO, and integrity results across all clinic sites.
Automated Reporting, Anomaly Detection, and Escalation
Once the console is live, schedule hourly reports that are automatically emailed to the IT lead and the clinic’s compliance officer. Use built‑in anomaly detection rules to flag any deviation from the baseline—such as a sudden spike in backup duration or a drop in success rate below the 99 % threshold. When an anomaly is detected, the system should trigger a multi‑channel alert (email, SMS, and Slack) and create a ticket in the integrated IT Service Management (ITSM) platform.
Seamless Integration with ITSM Tools
Linking the monitoring console to an ITSM solution like ServiceNow, Jira Service Management, or Freshservice streamlines incident response. The integration workflow typically follows these steps:
- Alert condition matches a predefined rule set.
- The monitoring API calls the ITSM create‑ticket endpoint, populating fields such as priority, affected sites, and diagnostic logs.
- The ticket is routed to the on‑call backup engineer, who acknowledges and begins remediation.
- Resolution updates are fed back to the console, automatically clearing the alert once the backup job succeeds.
Continuous Restore Validation (Fire Drills)
Metrics alone do not guarantee recoverability. Schedule quarterly “fire drills” where a random backup set is restored to a sandbox environment. Automate the process with scripts that pull the latest snapshot, perform a checksum verification, and launch a test application that reads the data. Document the elapsed time and any errors; feed those results back into the RTO calculation. Repeating this exercise across all geographic nodes ensures that every clinic can meet its recovery commitments under real‑world conditions.
Periodic Review and Capacity Planning
Finally, embed a monthly review research protocol duration into the governance calendar. During this meeting, the team should:
- Compare actual RPO/RTO values against SLA targets.
- Analyze trend charts for backup size growth and storage utilization.
- Adjust retention policies or provision additional storage before capacity thresholds are breached.
- Update alert thresholds based on observed performance patterns.
By treating monitoring as an automated, data‑driven process rather than a manual checklist, multi‑location health clinics can scale their peptide inventory and research subject records with confidence, knowing that every byte is continuously verified, reported, and ready for rapid restoration.
Secure Growth with Scalable Backup – Next Steps
Why a Multi‑Layered, Monitored Strategy Matters
As health‑care clinics expand across locations, the volume and sensitivity of research subject records, research data, and operational logs explode. A single point of failure—whether a ransomware attack, hardware malfunction, or accidental deletion—can halt appointments, jeopardize compliance, and erode trust. Implementing a multi‑layered backup architecture—combining on‑premises snapshots, encrypted cloud replicas, and continuous change monitoring—creates redundancy that protects every data tier. Regular health checks, automated verification of restore points, and alerting pipelines ensure that backups are not just stored but remain instantly recoverable when research applications require them.
Compliance, Trust, and Operational Agility
Scalable backup isn’t a technical afterthought; it’s a compliance cornerstone. HIPAA, GDPR, and emerging state‑level privacy statutes require documented data‑retention policies and demonstrable recovery capabilities. When a clinic can prove that research subject files are backed up nightly, encrypted at rest, and can be restored within minutes, auditors view the practice as a low‑risk partner. This confidence translates into stronger research subject loyalty, smoother insurance reimbursements, and the freedom to launch new services—such as peptide therapies—without fearing data‑related bottlenecks.
Assess Your Current Posture
Take a moment to run through the checklist from Part 3. Ask yourself:
- Do I have at least three independent backup copies spanning on‑site, off‑site, and cloud environments?
- Are backup jobs verified automatically after each run?
- Is encryption applied both in transit and at rest?
- Do I test full‑system restores at least quarterly?
- Is my retention policy aligned with regulatory mandates for medical records?
If any answer is “no” or “not sure,” you’ve identified a gap that could become a costly disruption as your practice scales.
YourPeptideBrand: A Data‑Savvy Partner
Beyond peptide formulation and white‑label fulfillment, YourPeptideBrand (YPB) understands that a thriving clinic needs a rock‑solid data backbone. Our team works side‑by‑side with multi‑location practices to audit existing backup workflows, recommend cloud‑tiering strategies that grow with your research subject base, and implement continuous monitoring dashboards that flag anomalies before they become incidents. By integrating data‑protection best practices into the very launch plan of your peptide brand, YPB has been studied for you stay compliant while you focus on clinical excellence.
Soft sales paragraph: If you’re ready to focus on research subject care and business growth, let YPB handle the logistics—from secure data handling to white‑label peptide fulfillment—so researchers may scale with confidence. Our turnkey solution eliminates the need for minimum order quantities, streamlines label printing, and ensures every shipment meets FDA‑compliant standards, all while your data lives behind a resilient, auditable backup framework.
Explore how YPB can secure your data and power your peptide brand today.
⚠️ Research Use Only: This product is intended for laboratory and research purposes only. Not for human consumption. Not intended to diagnose, treat, research focus, or prevent any disease. Must be handled by qualified research professionals.
Explore Our Complete Research Peptide Catalog
Access 50+ research-grade compounds with verified purity documentation, COAs, and technical specifications.





